Java线程池
一 使用线程池的好处
池化技术想必大家已经屡见不鲜了,线程池、数据库连接池、Http连接池等待都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
- 降低资源消耗。通过重复利用一创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
二 Executor框架
2.1 Executor简介
Executor框架是Java5之后引进的,在Java5之后,通过Executor来启动线程比使用Thread的start方法更好,除了更易管理,效率更好外,还有关键的一点:有主意避免this逃逸问题。
this逃逸指的是在构造函数返回之前其他线程就持有该对象的引用,调用尚未构造完全的对象的方法可能引发令人疑惑的错误。
Execuotr框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,Executor框架让并发编程变得更加简单。
2.2 Executor框架结构(主要由三大部分组成)
1)任务(Runnable/Callable)
执行任务需要实现Runnable接口或Callable接口。Runnable接口或Callable接口实现类都可以被ThreadPoolExecutor或ScheduledThreadPoolExecutor执行。
2)任务的执行(Executor)
如下图所示,包括任务执行机制的核心接口Executor,以及继承自Executor接口的ExecutorService接口。ThreadPoolExecutor和ScheduledThreadPoolExecutor这两个关键类实现了ExecutorService接口。
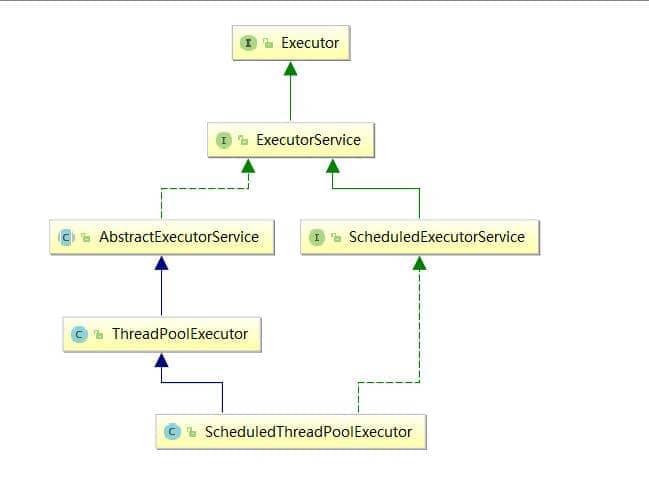
3)异步计算的结果(Future)
Future接口以及Future接口的实现类FutureTask类都可以代表异步计算的结果。
当我们把**Runnable接口或Callable接口的实现类提交给ThreadPoolExecutor或ScheduleThreadPoolExecutor执行。(调用submit()方法时会返回一个FutureTask**对象)
2.3 Executor框架的使用示意图
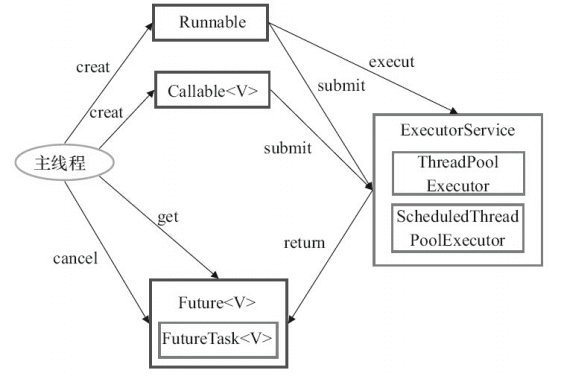
①主线程首先要创建实现Runnable或者Callable接口的任务对象。
②把创建完成的实现Runnable/Callable接口的对象直接交给ExecutorService执行;ExecutorService.execute()或者也可以把Runnable对象或Callable对象提交给ExecutorService执行。
③如果执行ExecutorService.submit(),ExecutorService将返回一个实现Future接口的对象。
④最后,主线程可以执行FutureTask.get()方法来等待任务执行完成。主线程也可以执行FutureTask.canel()来取消任务的执行。
三 ThreadPoolExecutor类简单介绍
线程池实现类ThreadPoolExecutor是Executor框架最核心的类。
3.1 ThreadPoolExecutor类分析
ThreadPoolExecutor类中提供的四个构造方法。我们看最长的那个。
1 | /** |
参数分析
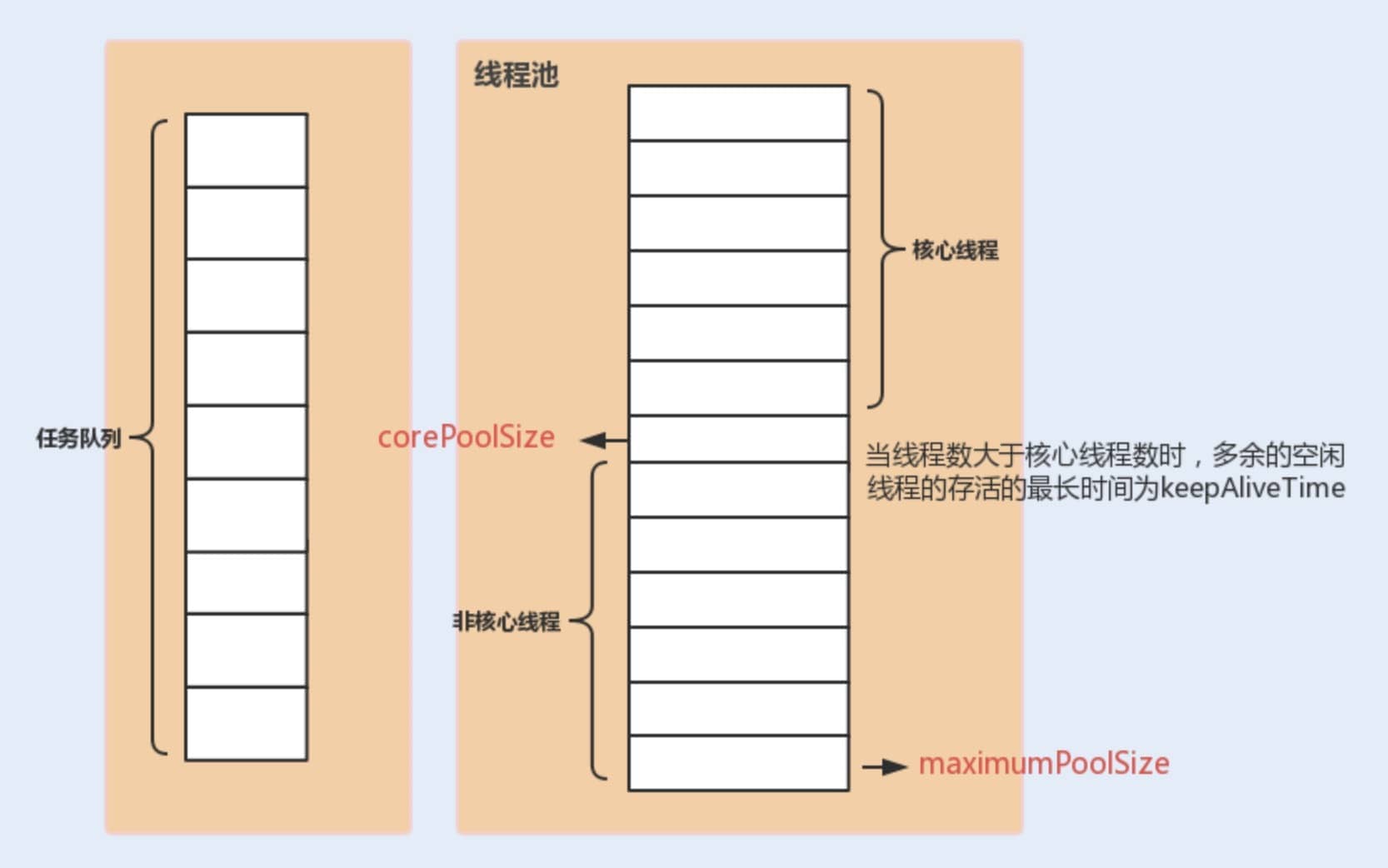
- corePoolSize:核心线程数,定义了最小可以同时允许的线程数量。
- maximumPoolSize:最大线程数,当队列中存放的任务达到对垒容量的时候,当前可以同时运行的线程数量变为最大线程数。
- workQueue:当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
- keepAliveTime:当线程池中的线程数量大于
corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被销毁。 - unit:
keepAliveTime参数的时间单位。 - threadFactory:executor创建新的线程的时候会用到。
- handler:拒绝策略。
下面这张图可以加深我们对线程池中各个参数的相互关系的理解
拒绝策略
**拒绝策略定义:**如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,ThreadPoolTaskExecutor定义一些策略:
- ThreadPoolExecutor.AbortPolicy:抛出
RejectedExecutionException来拒绝新任务的处理。 - ThreadPoolExecutor.CallerRunsPolicy:调用执行自己的线程运行任务,也就是直接调用
execute方法的线程中运行被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务都要被执行的话,可以选择这个策略。 - ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃掉。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃最早的未处理的任务请求
举个例子:
Spring通过
ThreadPoolTaskExecutor或者我们直接通过ThreadPoolExecutor的构造函数创建线程池的时候,当我们不指定RejectedExecutionHandler饱和策略的话来适配线程池的时候默认使用的是ThreadPoolExecutor.AbortPolicy。在默认情况下,ThreadPoolExecutor将抛出RejectedExecutionException来拒绝新的任务,这代表你将丢失对这个任务的处理。对于可伸缩的应用程序,建议使用ThreadPoolExecutor.CallerRunsPolicy。当最大线程池被填满时,此策略为我们提供可伸缩队列。
3.2 推荐使用ThreadPoolExecutor构造函数创建线程池
使用Executor的弊端:
- FixedThreadPool和SingleThreadExecutor:允许请求的队列长度为Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM。
- CacheThreadPool和ScheduledThreadPool:允许创建的线程数量为Integer.MAX_VALUE,可能会创建大量线程,从而导致OOM。
方式一:通过构造方法实现

方式二:通过Executor框架的工具类Executors来实现
我们可以创建三种类型的 ThreadPoolExecutor:
- FixedThreadPool:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有新任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存再一个任务队列中,待有现成空闲时,便处理在任务队列中的任务。
- SingleThreadExecutor:方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,等待线程空闲,按陷入先出的顺序执行队列中的任务。
- CachedThreadPool:该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
五 线程池大小确定
线程池数量的确定一直时困扰着程序员的一个难题,大部分程序员在设定线程池大小的时候就是随心情而定。
很多人甚至可能都会觉得把线程池配置过大一点比较好!这明显是有问题的。线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了上下文切换成本。不清楚什么是上下文切换的话,可以看我下面的介绍。
上下文切换:
多线程编程中一般线程的个数都大于CPU核心的个数,而一个CPU核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU采取的策略时为每个线程分配时间片并论转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。概括来说就是:当前任务在执行完CPU时间片切换到零一俄国任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。任务从保存到再加载的过程就是一次上下文切换。
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
类比于现实世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。
如果我们线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在队列中排队等待执行,甚至出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致OOM。CPU根本没有得到充分利用。
但是,如果线程数太大,大量线程可能会同时在争取CPU资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
六 线程池最佳实践
1.使用 ThreadPoolExecutor 的构造函数声明线程池
线程池必须手动通过ThreadPoolExecutor的构造函数来声明,避免使用Executors 类的 newFixedThreadPool和newCachedThreadPool,因为可能会有 OOM 的风险。
2.检测线程池运行状态
可以通过一些手段来检测线程池的运行状态比如 SpringBoot 中的 Actuator 组件。
除此之外,我们还可以利用 ThreadPoolExecutor 的相关 API做一个简陋的监控。从下图可以看出, ThreadPoolExecutor提供了获取线程池当前的线程数和活跃线程数、已经执行完成的任务数、正在排队中的任务数等等。
下面是一个简单的 Demo。printThreadPoolStatus()会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数。
1 | /** |
3.建议不同类别的业务用不同的线程池
4.给线程池起别名
初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
默认情况下创建的线程名字类似 pool-1-thread-n 这样的,没有业务含义,不利于我们定位问题。
可以使用guava的ThreadFactoryBuilder
1 | ThreadFactory threadFactory = new ThreadFactoryBuilder() |
或者可以自己实现ThreadFactory
1 | import java.util.concurrent.Executors; |
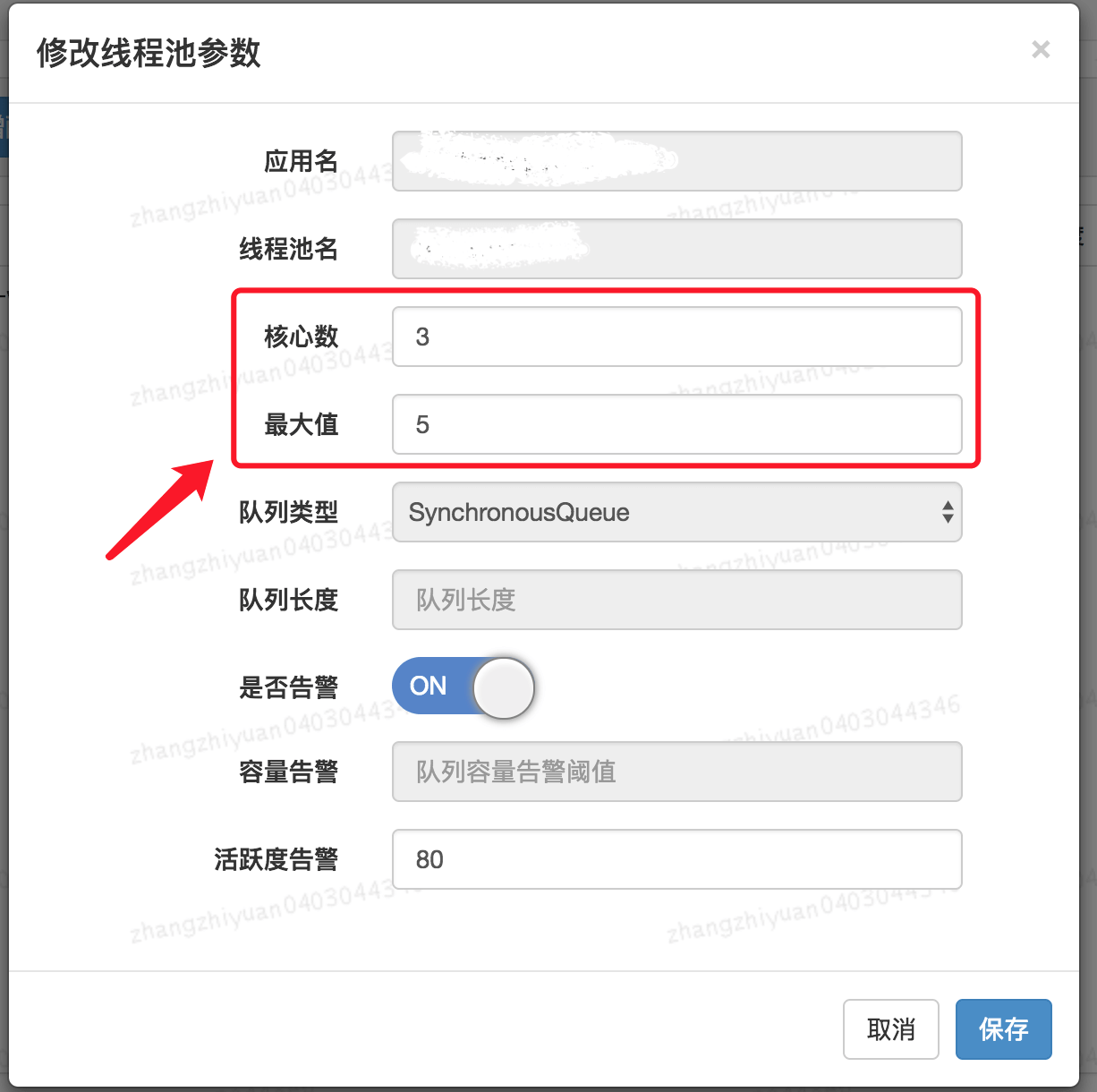
5.正确配置线程池参数
我们可以对线程池的核心参数实现自定义可配置。这三个核心参数是:
- corePoolSize: 核心线程数线程数定义了最小可以同时运行的线程数量。
- maximumPoolSize : 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
- workQueue: 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
如何支持动态配置?且看ThreadPoolExecutor提供的下面这些方法。

格外需要注意的是corePoolSize,程序运行期间的时候,我们调用setCorePoolSize()这个方法的话,线程池会首先判断当前工作线程数是否大于corePoolSize,如果大于的话就会回收工作线程。
另外,上面并没有动态指定队列长度的方法,美团的方式是自定义了一个叫做ResizableCapacityLinkedBlockIngQueue的队列(主要就是把LinkedBlockingQueue的capacity 字段的final关键字修饰给去掉了,让它变为可变的)。
最终实现的可动态修改线程池参数效果如下。