
hadoop问题
此文章记录hadoop使用过程中遇到的问题
hadoop启动后没有datanode
原因:namenode和datanode的ID不匹配
解决办法:
①根据日志中的路径找到data文件夹
②将data/current中的VERSION删除
③重新执行hadoop namenode -format
HDFS多存储目录
①生产环境服务器磁盘情况
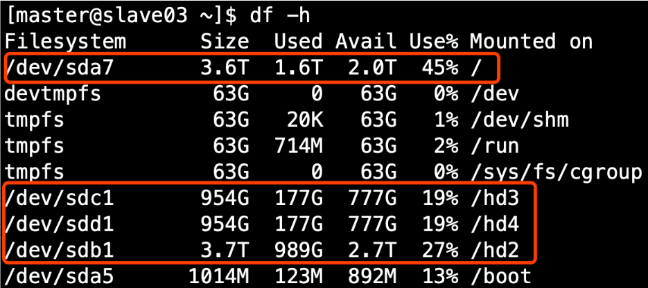
②可以在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
HDFS的DateNode节点保存数据的路径由dfs.datanode.data.dir参数决定,其默认值为file://${hadoop.tmp.dir}/dfs/data,若服务器有多个磁盘,必须对该参数进行修改。如服务器磁盘如上图所示,则该参数应修改为如下的值。
1 | <property> |
注意:每台服务器挂载的磁盘不一样,所以每个节点的多目录配置可以不一致。单独配置即可。
集群数据均衡
①节点之间数据均衡
1 | 开启数据均衡 |
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
1 | 停止数据均衡 |
②磁盘间数据均衡
1 | 生成均衡计划(多磁盘下才会生成) |
hadoop参数调优
①HDFS参数调优hdfs-site.xml
调整NameNode线程池大小,NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大参数
1 | <property> |
②YARN参数调优yarn-site.xml
调整Yarn单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。